Entry tags:
Онтологии: от философии к информатике. Часть четвертая, прикладная
Продолжение серии постов об онтологиях.
Те факторы, которые проблематичны уже в межчеловеческом общении, создают намного более серьёзные барьеры при обмене информацией между техническими процессами. В большинстве случаев при создании программ разработчики выбирают самый простой путь: они встраивают интерпретацию получаемых программой данных в процесс их обработки. К примеру, сервис, занимающийся поиском авиабилетов, получив от сервера авиакомпании значение
Безусловно, можно (и нужно) писать подробные спецификации к каждому интерфейсу, убеждаться, что разработчики читали эти спецификации (это уже намного сложнее) и тестировать программы перед использованием. К сожалению, это классическое решение не даёт 100% гарантии успеха даже для компактных и локальных систем. Если же мы имеем дело с распределённой системой, взаимодействующей с постоянно меняющимся количеством компонент, разрабытываемых совершенно разными людьми, то степень сложности резко возрастает. Одно из возможных решний заключается в использовании всеми компонентами общей структурированной контекстной информации. Особенно важно использование контекста в области ИИ, а также в двух относительно новых (касательно проектов и применения, а не первых публикаций) и активно развивающихся областях:
 Проект DBPedia посвящен автоматическому экспорту информации из Википедии и предоставлении её в структурированной форме для автоматической обработки программами. Это позволяет использовать Википедию в качестве контекстной базы данных, содержащей самую разную инрформацию обо всём подряд и поддерживающей сложные запросы. Несмотря на то, что информация не будет абсолютно точной, возможности её использования очень широки. Вспомним хотя бы программу, игравшую в Jeopardy, о которой я уже писал в одном из предыдущих постов.
Проект DBPedia посвящен автоматическому экспорту информации из Википедии и предоставлении её в структурированной форме для автоматической обработки программами. Это позволяет использовать Википедию в качестве контекстной базы данных, содержащей самую разную инрформацию обо всём подряд и поддерживающей сложные запросы. Несмотря на то, что информация не будет абсолютно точной, возможности её использования очень широки. Вспомним хотя бы программу, игравшую в Jeopardy, о которой я уже писал в одном из предыдущих постов.
 Стандарт Friend of a Friend (FOAF) позволяет описать взаимоотношения между людьми и предназначен для моделирования социальных сетей (и обработки информации из них), включая группы, интересы и т. д. Например, есть специальная поисковая машина. Стандарт не получил широкого распространения, из чего можно заключить, что NSA не участвовало в его разработке ;-) Используется также и вне сети (социология и т. п.) а также (благодаря наглядности) для формулировки примеров во многих публикациях. Между прочим, как раз LiveJournal и является крупнейшей платформой, поддерживающей FOAF.
Стандарт Friend of a Friend (FOAF) позволяет описать взаимоотношения между людьми и предназначен для моделирования социальных сетей (и обработки информации из них), включая группы, интересы и т. д. Например, есть специальная поисковая машина. Стандарт не получил широкого распространения, из чего можно заключить, что NSA не участвовало в его разработке ;-) Используется также и вне сети (социология и т. п.) а также (благодаря наглядности) для формулировки примеров во многих публикациях. Между прочим, как раз LiveJournal и является крупнейшей платформой, поддерживающей FOAF.
А вот тематика проекта BioPortal намного серьёзней: это большая база, в которой собраны в структурированной форме данные из области биологии (не только человека) и медицины. Там есть данные из исследований генома, из фармакологии, анатомии, данные по симптоматике и диагностике и многое, многое другое. С главной страницы проекта, а также со страницы в Википедии есть сноски на разные поисковые машины, с помощью которых можно покопаться в этих данных. Вот только ипохондрикам туда соваться очень не советую ;-)
Ну и напоследок представлю проект-монстр Linked Open Data (LOD). Монструозность его заключается в том, что он ставит своей целью связать в одну базу все онтологии, находящиеся в публичном доступе. Вообще все. Да-да и FOAF и вышеописанные Open Biomedical Ontologies и DBPedia и многое другое уже там. Примерное представление об этой супер-базе дает графика из Википедии, в кооторой каждая база обозначена кружком, чей цвет соответствует какой-то области знаний:

Визуализация структуры LOD на момент сентября 2011 года (клик на картинку откроет её в полную величину).
Для храниния распределенных разнородных данных и поддержки запросов к ним подобного рода нужны специальные технологии (обычная реляционная база данных для этого подходит плохо). Онтологические даные хранят в так называемых "базах знаний", которые в той или иной форме фигурируют в исследовательских работах и прикладных проектах еще с 70-х годов. Современные формы появились с идеей использования онтологий именно в Интернете. О них я напишу в следующей части.
Те факторы, которые проблематичны уже в межчеловеческом общении, создают намного более серьёзные барьеры при обмене информацией между техническими процессами. В большинстве случаев при создании программ разработчики выбирают самый простой путь: они встраивают интерпретацию получаемых программой данных в процесс их обработки. К примеру, сервис, занимающийся поиском авиабилетов, получив от сервера авиакомпании значение
[max_free_luggage=20], интерпретирует его как "максимальный вес бесплатного багажа в килограммах". Пассажир, чей багаж весит 25 кг, такой билет не купит, потому что не видит, что сервис проигнорировал второй, неизвестный ему параметр [max_luggage_pieces=2], означавший, что вышеуказанный вес был определён для каждого из двух включённых в цену чемоданов. Хуже, если пассажир купит билет, упакует 18-килограммовый чемодан и уже в аэропорту узнает, что максимальный вес был указан действительно за все чемоданы, но в фунтах. И если вы полагаете, что доплата за лишние 9 кг в этом случае - это мелочь, то подумайте о космическом аппарате NASA "Mars Climate Orbiter" стоимостью 125 миллионов долларов (это не считая стоимости исследовательских работ), который сгорел в марсианской атмосфере именно из-за того, что с Земли ему передали данные в британских единицах вместо метрических.Безусловно, можно (и нужно) писать подробные спецификации к каждому интерфейсу, убеждаться, что разработчики читали эти спецификации (это уже намного сложнее) и тестировать программы перед использованием. К сожалению, это классическое решение не даёт 100% гарантии успеха даже для компактных и локальных систем. Если же мы имеем дело с распределённой системой, взаимодействующей с постоянно меняющимся количеством компонент, разрабытываемых совершенно разными людьми, то степень сложности резко возрастает. Одно из возможных решний заключается в использовании всеми компонентами общей структурированной контекстной информации. Особенно важно использование контекста в области ИИ, а также в двух относительно новых (касательно проектов и применения, а не первых публикаций) и активно развивающихся областях:
- Автоматический обмен разнородной информацией разнородными распределенными устройствами. Мы говорим не только о изъезженном (и IMHO утопическом) примере холодильника, самостоятельно дозаказывающем продукты по Интернету. На практике это интересно для систем сенсоров и транспондеров в системах удаленного контроля и безопасности, в логистике и сложных конвейерных системах. В литературе всё это часто публикуется под общим термином "Internet of Things".
- Анализ и автоматизированное использование информации, публикуемой в WWW. Речь идёт как об интеграции разнородных информационных систем, так и об улучшенном поиске. Хотя современные поисковые машины дают хорошие результаты, интерпретация сложных структурированных вопросов и предоставление конкретных ответов (вместо сноски на страницу с похожим текстом) для них, в большинстве случаев, недоступны. В качестве простого примера предлагаю попробовать одним запросом найти фамилию зятя девятого президента США. Для подобных разработок и методик используется общий термин "Semantic Web".
Проект DBPedia посвящен автоматическому экспорту информации из Википедии и предоставлении её в структурированной форме для автоматической обработки программами. Это позволяет использовать Википедию в качестве контекстной базы данных, содержащей самую разную инрформацию обо всём подряд и поддерживающей сложные запросы. Несмотря на то, что информация не будет абсолютно точной, возможности её использования очень широки. Вспомним хотя бы программу, игравшую в Jeopardy, о которой я уже писал в одном из предыдущих постов. Стандарт Friend of a Friend (FOAF) позволяет описать взаимоотношения между людьми и предназначен для моделирования социальных сетей (и обработки информации из них), включая группы, интересы и т. д. Например, есть специальная поисковая машина. Стандарт не получил широкого распространения, из чего можно заключить, что NSA не участвовало в его разработке ;-) Используется также и вне сети (социология и т. п.) а также (благодаря наглядности) для формулировки примеров во многих публикациях. Между прочим, как раз LiveJournal и является крупнейшей платформой, поддерживающей FOAF.А вот тематика проекта BioPortal намного серьёзней: это большая база, в которой собраны в структурированной форме данные из области биологии (не только человека) и медицины. Там есть данные из исследований генома, из фармакологии, анатомии, данные по симптоматике и диагностике и многое, многое другое. С главной страницы проекта, а также со страницы в Википедии есть сноски на разные поисковые машины, с помощью которых можно покопаться в этих данных. Вот только ипохондрикам туда соваться очень не советую ;-)
Ну и напоследок представлю проект-монстр Linked Open Data (LOD). Монструозность его заключается в том, что он ставит своей целью связать в одну базу все онтологии, находящиеся в публичном доступе. Вообще все. Да-да и FOAF и вышеописанные Open Biomedical Ontologies и DBPedia и многое другое уже там. Примерное представление об этой супер-базе дает графика из Википедии, в кооторой каждая база обозначена кружком, чей цвет соответствует какой-то области знаний:
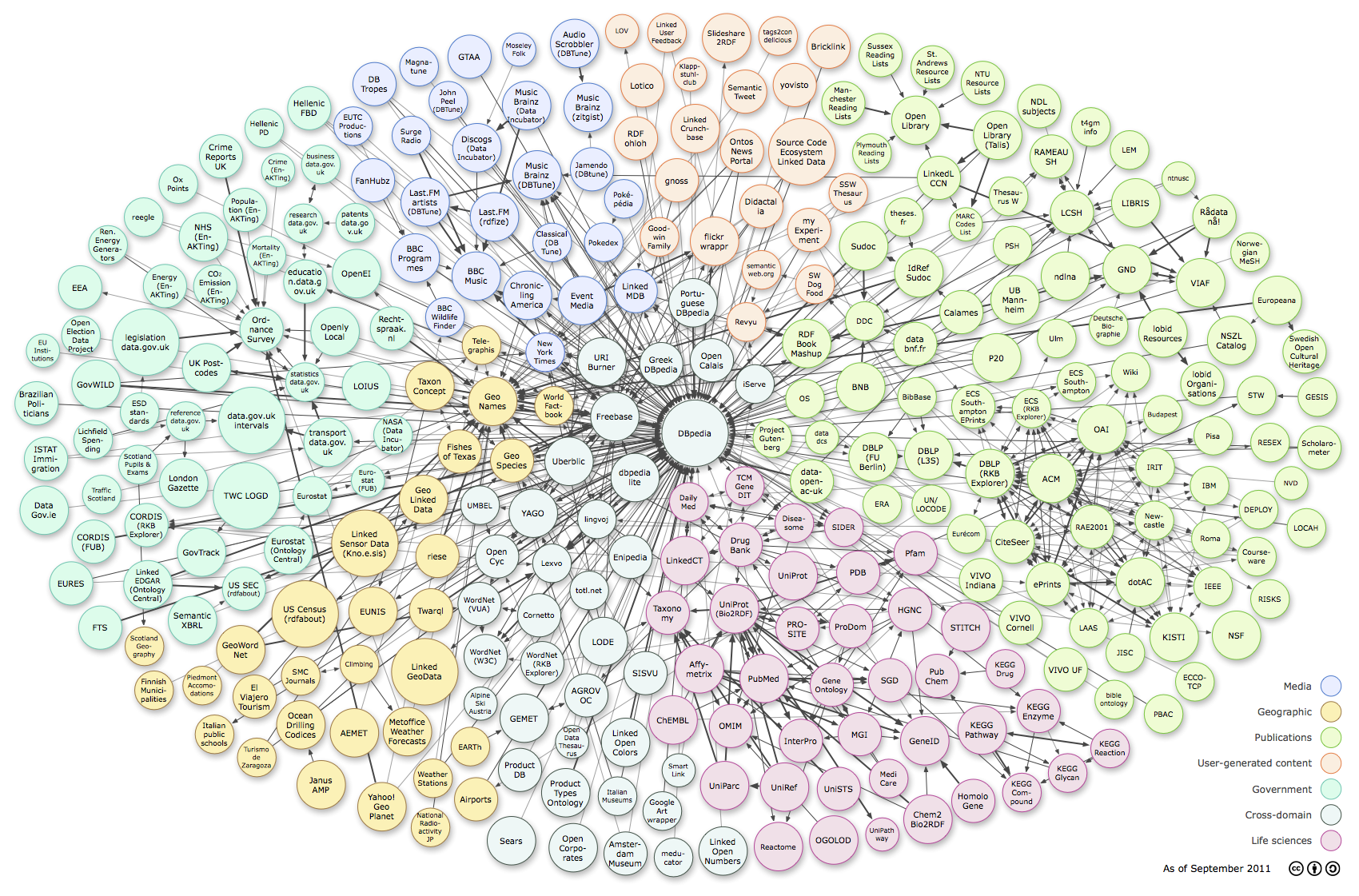
Визуализация структуры LOD на момент сентября 2011 года (клик на картинку откроет её в полную величину).
Для храниния распределенных разнородных данных и поддержки запросов к ним подобного рода нужны специальные технологии (обычная реляционная база данных для этого подходит плохо). Онтологические даные хранят в так называемых "базах знаний", которые в той или иной форме фигурируют в исследовательских работах и прикладных проектах еще с 70-х годов. Современные формы появились с идеей использования онтологий именно в Интернете. О них я напишу в следующей части.